Voice AI Platform
Conversational Intelligence for Every Device
Embedded AI that enhances Speech, understands speakers, and enables natural Voice Interactions across automotive, consumer, conferencing, and Edge AI Devices.
AI Noise Reduction
Speaker ID
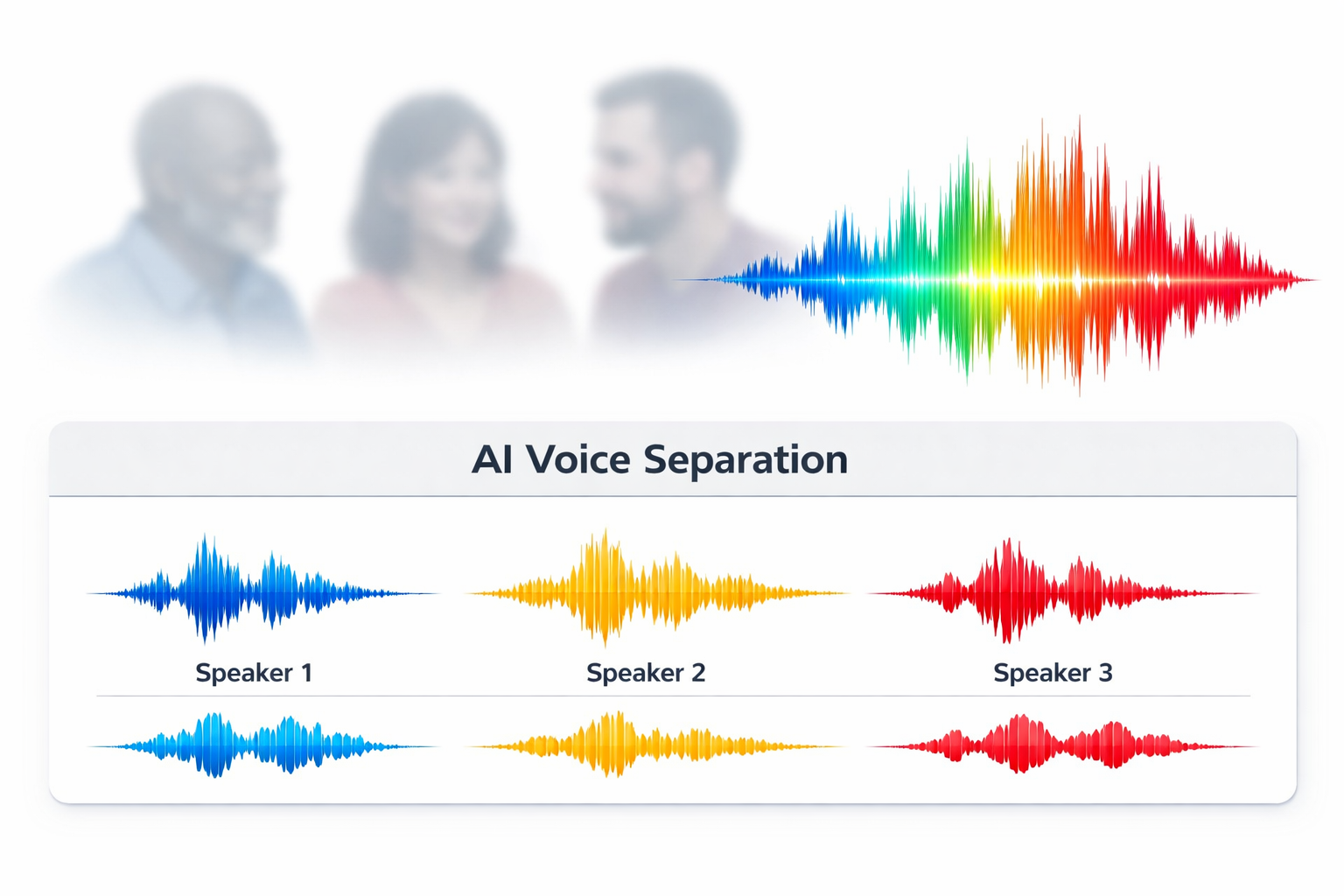
Voice Separation
Edge Inference
40dB+
Noise Suppression
⚡
<20ms
Processing Latency

AMI Voice AI — On-Device Processing

Automotive

Hearables